Designing a Comprehensive Course in Distributed Systems: Reading List
September 10, 2018 · Filed in Distributed SystemsIn a recent conversation at work, I learned about MIT’s distributed systems course. As the majority of the content is available online through the course website, I was just about ready to dive in, follow the course, and report on what I learned. But then I had this thought: I am not formally a student anymore, so I should take more ownership of my learning. I should design my own comprehensive course in distributed systems!
My course doesn’t have to be constrained to a semester in length or only lightly cover topics that I find important and compelling. I’ll be able to take a more depth-first approach to learning. For example, after implementing the Raft consensus algorithm, if I feel like there is more to learn, I can take time to build an simple system which uses my Raft code. A university course on a broad topic such as distributed systems has to avoid depth like this in order to cover all the required content. As someone who has been in industry for a few years, I also have a rough idea of which concepts matter in practice because I’ve run up against them and struggled to find time to understand them as well as I wanted.
Why study distributed systems?
First, some motivation. Of all the things to learn about in our field, why study distributed systems? In that same conversation I mentioned above, one of my coworkers said it better than I could:
Developers really need to know how to deal with concurrency, think in that space, and stop thinking about programs as serial lists of instructions. There is no demand for someone who can’t natively think about concurrency all over their algorithm and their code.
He went on to argue that an understanding of distributed systems is becoming a hard prerequisite of work done by software developers. While testing and software practice can safely and easily be learned on the job, concepts related to asynchronous concurrent systems often cannot be. Misunderstandings in this regard lead to system outages and incur serious technical debt. To avoid making common mistakes and architecting poor systems, it’s critical to take time to seriously learn distributed systems.
Personally, I feel like I have a good grasp of the fundamentals, but an important next step in my career is learning advanced concepts like consensus and broadcast. Understanding abstractions a level or two below your usage is incredibly worthwhile, not to mention satisfying. I want to understand the content necessary to be considered a so-called “distributed systems engineer.” I also think that a few years of distributed systems practice in industry have primed me to better understand these concepts. I’ve covered many of them at a high level, so revisiting them with a new perspective will be helpful.
Creating a reading list
What follows is a reading list to capture the breadth of the available content in distributed systems. I’ll use it in my next blog post to design the schedule of my course. To create this list, I scoured the internet, literally following hundreds of links. If you are also interested in this topic, I recommend you do the same: make your own reading list that gets you excited to learn more. These are the resources I found most useful in creating my reading list:
- Awesome Distributed Systems
- Christopher Meiklejohn: Readings in Distributed Systems
- The Paper Trail: necessary distributed systems theory and recommendations
- MIT 6.824 Distributed Systems course schedule
- MIT Distributed Systems Reading Group Paper List
Distributed systems research is known for an abundance of papers. My reading list includes papers as they are the primary source of information in this field of study. Papers are also challenging and I want to get better at understanding them and using them as part of my learning.
Concepts
Basics
The basics give a sense for why distributed systems present challenging problems. With the problems framed, it will make more sense why we have to think so carefully about the advanced concepts below. For example, understanding that the network is unreliable and packets regularly get dropped makes it clear why it’s hard to get multiple nodes of a database to agree on the state of the data.
- Distributed Systems for Fun and Profit
- Free book that was recommended by several articles
- Scalable Web Architecture and Distributed Systems
- Chapter from a free book, The Architecture of Open Source Applications
- Introduces the building blocks of distributed systems, including caches, indexes, load balancers, and queues
- Notes on Distributed Systems for Young Bloods
- Short blog post written by an experienced distributed systems engineer with an audience of new engineers
- Calls out that coordination is hard, failure of individual components is common, and that metrics and percentiles enable visibility
- Failure Modes in Distributed Systems
- Short blog post which explains what could otherwise be confusing terminology of types of failure (performance, omission, fail-stop, crash, etc).
- An Introduction to Distributed Systems
- Outline to a course taught by Kyle Kingsbury, the creator of the distributed systems tester Jepsen
- Kyle Kingsbury has also given several talks which are available on the Jepsen website
- Microservices: Are We Making a Huge Mistake?
- My previous blog post which covered Microservices (a software development technique for building a software system that runs on a distributed system) and some of the Fallacies of Distributed Computing
- See this more detailed Explanation of the Fallacies as well
Consensus
The problem of achieving consensus is fundamental to distributed systems. These first several papers are true classics and known well by distributed systems engineers.

- The Byzantine Generals Problem (Lamport 1982)
- One of the classic papers which presents a fictitious scenario in war to explain a problem faced by any distributed system
- Time, Clocks, and the Ordering of Events in a Distributed System (Lamport 1978)
- Distributed systems classic and primer by Lamport
- Distributed Snapshots: Determining Global States of a Distributed System (1984)
- Impossibility of Distributed Consensus with One Faulty Process (1985)
- “One of the most important results in distributed systems theory was published in April 1985 by Fischer, Lynch and Patterson. Their short paper ‘Impossibility of Distributed Consensus with One Faulty Process’, which eventually won the Dijkstra award given to the most influential papers in distributed computing, definitively placed an upper bound on what it is possible to achieve with distributed processes in an asynchronous environment.”1
- A Brief Tour of FLP Impossibility
Paxos
Paxos is a solution to consensus proposed by Lamport himself, the author of several of the classic papers above. You’ll hear his name a lot in distributed systems. It’s known to be difficult to understand, yet was implemented in several successful distributed systems like Google’s Chubby lock service.
- Paxos Made Simple (2001)
- A shorter and easier to understand explanation of Paxos paper by Lamport
- Paxos Made Live (2007)
- “We describe our experience building a fault-tolerant database using the Paxos consensus algorithm. Despite the existing literature in the field, building such a database proved to be non-trivial.”
- Google’s learning while implementing systems atop of Paxos. Demonstrates various practical issues encountered while implementing a theoretical concept …
- Using Paxos to Build a Scalable, Consistent, and Highly Available Datastore (2011)
- Describes the experimental datastore Spinnaker which utilizes Paxos replication
Two-phase and three-phase commit (2PC and 3PC)
2PC and 3PC do not attempt to solve consensus entirely. Instead, they limited in scope to transaction commit protocols. They are often compared to Paxos as understanding their differences is insightful.
Raft
Raft, which is much newer than Paxos (2013 compared to 1989), is meant to be a simplified, understandable version of Paxos. It has quickly become a core part of the backbone of distributed systems as it’s used in open source software like etcd and Consul.
- In Search of an Understandable Consensus Algorithm (Extended Version)
- “Raft is a consensus algorithm for managing a replicated log. It produces a result equivalent to (multi-)Paxos, and it is as efficient as Paxos, but its structure is different from Paxos; this makes Raft more understandable than Paxos and also provides a better foundation for building practical systems.”
- Visualization of Raft
- Interactive visualization of the consensus algorithm to explain concepts like distributed consensus, leader election, and log replication
- Consul: Raft Protocol Overview
- Consul implements Raft. This page describes Raft and how it is used
- etcd
- “etcd is written in Go and uses the Raft consensus algorithm to manage a highly-available replicated log.”
- MIT 6.824 Lab 2: Raft
- “In this lab you’ll implement Raft, a replicated state machine protocol. In the next lab you’ll build a key/value service on top of Raft. Then you will shard your service over multiple replicated state machines for higher performance.”
- MIT 6.824 Lab 3: Fault-tolerant Key/Value Service
- “In this lab you will build a fault-tolerant key/value storage service using your Raft library from lab 2. You key/value service will be a replicated state machine, consisting of several key/value servers that use Raft to maintain replication. Your key/value service should continue to process client requests as long as a majority of the servers are alive and can communicate, in spite of other failures or network partitions.”
Broadcast
Atomic or total order broadcast
Atomic broadcast is exactly as hard as consensus - in a precise sense, if you solve atomic broadcast, you solve consensus, and vice versa.2
- Wikipedia: Atomic broadcast
- ZooKeeper’s atomic broadcast protocol: Theory and practice (2012)
- ZooKeeper Atomic Broadcast (ZAB) protocol is what enables ZooKeeper’s fault tolerance
- “At its core lies an atomic broadcast protocol, which elects a leader, synchronizes the nodes, and performs broadcasts of updates from the leader. We study the design of this protocol, highlight promised properties, and analyze its official implementation by Apache. In particular, the default leader election protocol is studied in detail.”
Gossip-based broadcast
- Wikipedia: Gossip protocol
- SWIM: Scalable Weakly-consistent Infection-style Process Group Membership Protocol
- hashicorp/memberlist
- “The use cases for such a library are far-reaching: all distributed systems require membership, and memberlist is a re-usable solution to managing cluster membership and node failure detection.”
- Based on the SWIM protocol with some adaptions
- Pilosa’s use of hashicorp/memberlist for Gossip
- Serf
- Serf: Gossip Protocol
- “Serf uses a gossip protocol to broadcast messages to the cluster. … [The protocol] is based on “SWIM: Scalable Weakly-consistent Infection-style Process Group Membership Protocol”, with a few minor adaptations, mostly to increase propagation speed and convergence rate.”
- Practical Golang: Building a simple, distributed one-value database with Hashicorp Serf
Availability, replication, and partitioning
- Distributed Systems: Take Responsibility for Failover
- Short blog post that argues that systems capable of automatically making failover decisions lead to improved maintainability
- Highly Available Transactions: Virtues and Limitations
- “In this work, we consider the problem of providing Highly Available Transactions (HATs): transactional guarantees that do not suffer unavailability during system partitions or incur high network latency.”
- Distributed state machine replication
- MIT 6.824 Lab 4: Sharded Key/Value Service
- “In this lab you’ll build a key/value storage system that “shards,” or partitions, the keys over a set of replica groups. A shard is a subset of the key/value pairs; for example, all the keys starting with “a” might be one shard, all the keys starting with “b” another, etc. The reason for sharding is performance. Each replica group handles puts and gets for just a few of the shards, and the groups operate in parallel; thus total system throughput (puts and gets per unit time) increases in proportion to the number of groups.”
Eventual consistency
Eventual consistency is a response to challenge of creating fault-tolerant systems. It implies weaker guarantees about how the system will behave when faults occur.
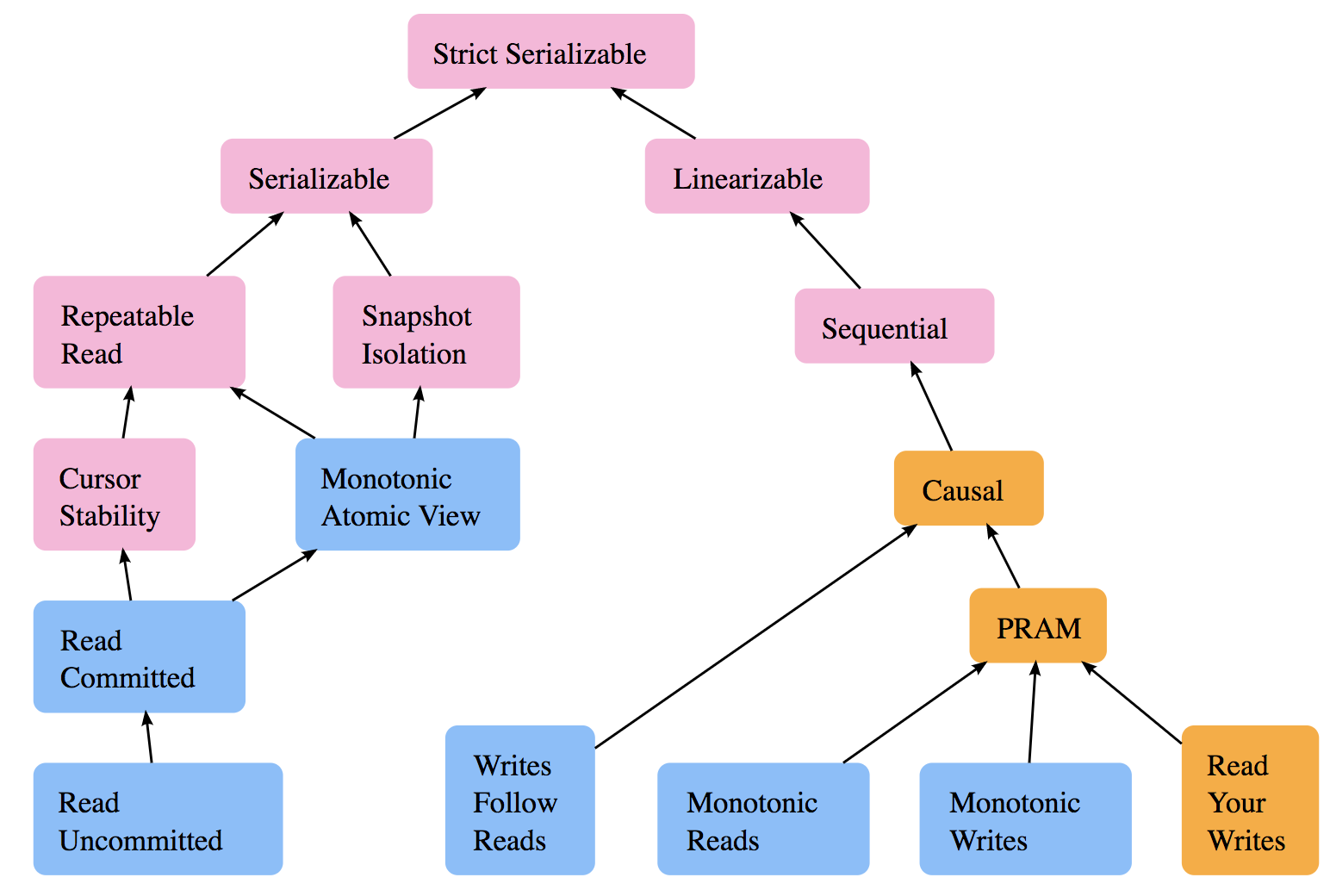
- Consistency Models
- Prerequisite to the other resources; defines the terminology used when discussing consistency
- Graph showing the relationships between consistency models in databases like Strict Serializable and Linearizability
- Life beyond Distributed Transactions
- “This paper explores and names some of the practical approaches used in the implementations of large-scale mission-critical applications in a world which rejects distributed transactions.”
- Consistency Tradeoffs in Modern Distributed Database System Design
- Building on Quicksand
- “Emerging patterns of eventual consistency and probabilistic execution may soon yield a way for applications to express requirements for a “looser” form of consistency while providing availability in the face of ever larger failures.”
- Eventually Consistent - Revisited
- Great discussion of the tradeoffs one makes in choosing eventual consistency
- There is No Now
- Reminder of the impossibility of instantaneous communication and the implications for distributed systems
- A Critique of the CAP Theorem
- “In this paper we survey some of the confusion about the meaning of CAP, including inconsistencies and ambiguities in its definitions, and we highlight some problems in its formalization. CAP is often interpreted as proof that eventually consistent databases have better availability properties than strongly consistent databases; although there is some truth in this, we show that more careful reasoning is required. These problems cast doubt on the utility of CAP as a tool for reasoning about trade-offs in practical systems.”
- Also see this auxiliary post by the author, Please stop calling databases CP or AP
Tangential concepts
Concepts/technologies that often come up in a discussion of distributed systems, but did not fit well into any of the other sections.
Distributed systems in the wild
Distributed systems theory becomes practical through its implementation in production systems. Studying successful systems of this nature like Spanner, Kafka, and Dynamo is exceptionally interesting and valuable.
- The Google File System (2003)
- Example of a distributed file system
- MapReduce (2004)
- MIT 6.824 Lab 1: MapReduce “In this lab you’ll build a MapReduce library as an introduction to programming in Go and to building fault tolerant distributed systems. In the first part you will write a simple MapReduce program. In the second part you will write a Master that hands out tasks to MapReduce workers, and handles failures of workers. The interface to the library and the approach to fault tolerance is similar to the one described in the original MapReduce paper.”
- Bigtable: A Distributed Storage System for Structured Data (2006)
- “Bigtable is a distributed storage system for managing structured data that is designed to scale to a very large size: petabytes of data across thousands of commodity servers.”
- Chubby Lock Manager (2006)
- Google’s lock management service. Sometimes referred to as “Paxos as a Service” used by other distributed systems.
- Inspired other service discovery tools like Consul and etcd
- Spanner: Google’s Globally-Distributed Database (2012)
- “The lack of transactions in Bigtable led to frequent complaints from users, so Google made distributed transactions central to Spanner’s design. Based on its experience with Bigtable, Google argues that it is better to have application programmers deal with performance problems due to overuse of transactions as bottlenecks arise, rather than always coding around the lack of transactions.”3
- Scaling Memcache at Facebook
- Dynamo: Amazon’s Highly Available Key-value Store (2007)
- Describes a highly available and fault tolerant database
- Inspired Cassandra and other similar databases
- Cassandra: A Decentralized Structured Storage System (2009)
- ZooKeeper: Wait-free coordination for Internet-scale systems (2010)
- Distributed coordination service used by other distributed systems like Kafka
- Kafka: a Distributed Messaging System for Log Processing (2011)
- “We introduce Kafka, a distributed messaging system that we developed for collecting and delivering high volumes of log data with low latency.”
- The Tail at Scale
- Article that asserts that the challenge of keeping the tail of the latency distribution low is critical in interactive services
- Managing Critical State: Distributed Consensus for Reliability
- Chapter 23 of Google’s phenomenal book, Site Reliability Engineering: How Google Runs Production Systems
- Practical exploration of using distributed consensus for increased reliability
Resources
Blogs
- High Scalability
- All Things Distributed
- “Werner Vogels’ weblog on building scalable and robust distributed systems.”
- Martin Kleppmann’s Blog
- Author of Designing Data Intensive Applications, which has a chapter that covers distributed systems theory
Courses
- Carnegie Mellon University: Distributed Systems
- University of Washington: Distributed Systems
- MIT 6.824: Distributed Systems Engineering
I found these courses in this curated list of awesome Computer Science courses available online. Here is a similar list, except it focuses on courses using Go, many of which cover concurrency and distributed systems.
Metadata and Navigation
Subscribe
Subscribe via my newsletter or RSS feed